관계형 모델
- 관계 모델에서 데이터베이스는 릴레이션(테이블)들의 모임으로 표현됨
- 릴레이션은 튜플(행, 레코드)들의 집합으로 표현됨
- 튜플은 애트리뷰트(칼럼, 필드, 혹은 속성)들로 구성됨
● 관계 모델의 용어
- 행 : 튜플
- 열 : 애트리뷰트 (속성)
- 테이블 : 릴레이션
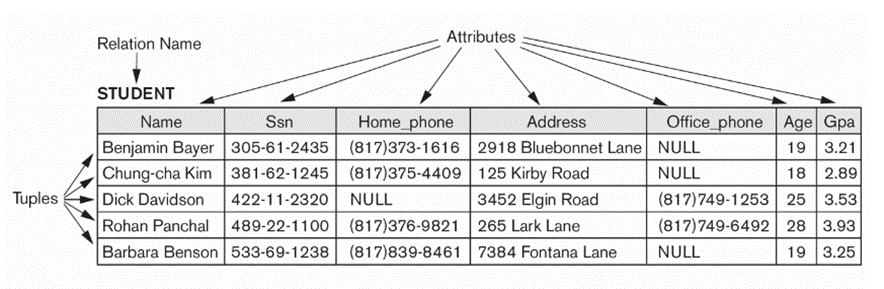
릴레이션과 관련된 용어들
● 도메인(domain) : 원자 값들(atomic values)의 집합
- Names : 개인의 이름들의 집합
- Age : 16~60 사이의 사원들의 나이 (정수)
- Dom(gender)={‘M’,’W’}
- Dom(class)={1,2,3,4}
● 도메인은 실제 데이터 타입으로 명시함 (int, char(10), …)
● 릴레이션 스키마 (Relation schema)
- 릴레이션 이름 R과 애트리뷰트 Ai들의 집합으로 R(A1, A2, … , An)로 표기함
- 예 : STUDENT(Name, SSN, BirthDate, Addr)
- 릴레이션의 차수 (degree) : 릴레이션의 애트리뷰트 개수
- 릴레이션 R(A1, A2, … , An)의 튜플 t : n-튜플
- 값들의 (순서화된) 집합 t = <v1, v2, … , vn>
- vi는 dom(Ai)의 한 원소임.
- R에 대한 릴레이션 혹은 릴레이션 인스턴스 (Relation instance) : r(R)
● 튜플의 집합 : r(R) = {t1, t2, …, tm}
● r(R) ⊆ dom(A1) X … X dom(An)
● X : 카티션 곱 (cartesian product)
릴레이션의 특징
● 릴레이션에서 튜플의 순서는 의미가 없음
- 집합에서 원소의 순서가 무의미한 것과 마찬가지
● 각 튜플 내에서의 값들의 순서
- n-튜플은 n개 값으로 구성된 리스트이며, 한 튜플 내에서 값들의 순서는 중요함 (리스트에서 원소의 순서는 중요한 의미를 가짐)
● 튜플 내의 필드 값
- 나눌 수 없는 원자 값들(atomic values) 임
- 값을 알 수 없거나 해당되는 값이 없을 때에는 null이라는 특수 값을 사용함
- ER 모델에서의 다치(multi-valued) 애트리뷰트나 복합(composite) 애트리뷰트는 관계 모델에서 허용되지 않음

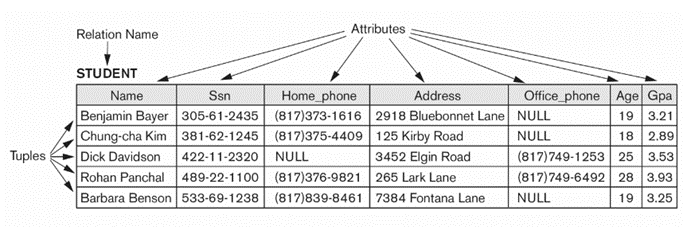
☞ 위 2개의 릴레이션은 튜플의 순서만 다를 뿐 같은 릴레이션이다.
Q) 첫 번째 tuple에서 열 번째 tuple까지 불러오기 => False => 집합에는 순서가 없기 때문
관계형 모델 표기법
- 차수가 n인 릴레이션 스키마 R은 R(A1, A2, … , An)으로 표기한다
- 릴레이션 r(R)의 n-튜플 t는 t=<v1, v2, … , vn>으로 표기한다. vi는 애트리뷰트 Ai의 값이다.
- 튜플 t의 구성요소 값(component value)을 t [Ai] = <vi> (튜플 t에 대한 애트리뷰트 Ai의 값)로 표기한다.
- t [A1, A2, … , An]는 애트리뷰트 A1, A2, … , An의 값을 포함하는 부(sub)-튜플을 가리킨다.
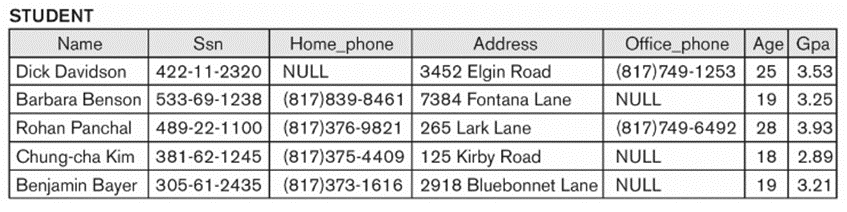
☞ t=<Benjamin Bayer, 305-61-2435 …>
☞ t [Age, Gpa] = <19, 3.21>
- 대문자 Q, R, S 등은 릴레이션 이름을 나타낸다.
- 소문자 q, r, s 등은 릴레이션 상태를 나타낸다.
- 소문자 t, u, v 등은 튜플을 나타낸다.
- STUDENT처럼 릴레이션 스키마의 이름은 릴레이션의 현재 튜플들의 집합, 즉, 현재의 릴레이션 상태를 가리키고, STUDENT(Name, SSN, …)는 릴레이션 스키마를 가리킨다.
- 서로 다른 릴레이션에서 동일한 이름의 애트리뷰트를 사용할 수 있으며, 애트리뷰트 이름 앞에 릴레이션 이름을 붙여서 서로를 구분한다.
'데이터베이스(DB)' 카테고리의 다른 글
| 관계형 모델 제약조건 (0) | 2022.10.08 |
|---|---|
| DBMS의 분류 (0) | 2022.10.08 |
| 데이터베이스 시스템과 아키텍처 (2) (0) | 2022.10.05 |
| 데이터베이스 시스템과 아키텍처 (1) (0) | 2022.10.05 |
| 데이터베이스 소개 (0) | 2022.10.03 |


