1. 내장 함수
데이터를 불러온다.
import pandas as pd
df = pd.read_csv('cafe4.csv') # https://kdh9797-devwiki.tistory.com/85
df.head()

1-1. len()
데이터프레임에서 행(row)의 수를 반환한다.
행의 수를 구하는 다른 방법은 df.shape을 사용한다.
df.shape [0]은 행의 수, df.shape [1]은 열의 수이다.
# 데이터프레임의 행의 수 구하기
print(len(df))
print(df.shape[0])
8
8
1-2. sum()
sum()은 합계 함수이다.
예를 들어 '가격이 5000보다 크다'라는 조건에 맞는 데이터 수를 구한다고 하자.
df['가격'] > 5000

이때 True는 1, False는 0이므로 조건에 맞는 데이터의 개수를 구하면 3이 나올 것이다.
즉, '가격이 5000보다 크다'라는 조건을 만족하는 데이터는 3개다.
print(sum(df['가격'] > 5000))
print(len(df[df['가격'] > 5000]))
3
3
컬럼별 합계를 구할 수 있다.
df.sum(numeric_only=True)

만약 행별로 합계를 구한다면 축(axis)을 변경하여 합계를 구한다.
# 행별 합계
df.sum(axis=1, numeric_only=True)

※ sum()과 drop() axis 차이
| axis = 0 (기본값) | axis = 1 | |
| drop() | 행삭제 | 컬럼 삭제 |
| sum() | 컬럼별 합계 | 행 합계 |
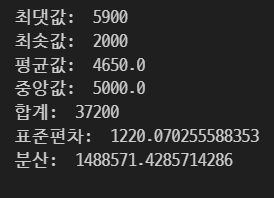
1-3. 통계 함수
print('최댓값: ', df['가격'].max())
print('최솟값: ', df['가격'].min())
print('평균값: ', df['가격'].mean())
print('중앙값: ', df['가격'].median())
print('합계: ', df['가격'].sum())
print('표준편차: ', df['가격'].std())
print('분산: ', df['가격'].var())
1-4. quantile()
quantile() 함수는 0~1 사이 값을 통해 분위수를 확인할 수 있다.
0.25 : 1 사분위수 (데이터 하위 25%)
0.5 : 2 사분위수 (데이터 중앙값)
0.75 : 3 사분위수 (데이터 하위 75%)
quantile() 함수에 숫자 (파라미터)를 넣을 때 1 사분위수를 구한다면 '0.25'를 입력 또는 '. 25'를 입력한다.
print('분위수 25% 값: ', df['가격'].quantile(.25))
print('분위수 75% 값: ', df['가격'].quantile(.75))

# 가격이 하위 25% 보다 작은 가격을 출력
df[df['가격'].quantile(.25) > df['가격']]

# 가격이 상위 25% 보다 큰 가격을 출력
df[df['가격'].quantile(.75) < df['가격']]

1-5. mode()
mode()는 최빈값을 찾을 때 활용한다.
최빈값을 찾아 시리즈 형태로 반환한다.
df['원산지'].mode()

최빈값만 얻고 싶다면 인덱스 0을 붙여준다.
df['원산지'].mode()[0]
'코스타리카'
1-6. idxmax()와 idxmin()
idxmax()는 최댓값을 갖는 인덱스, idxmin()은 최솟값을 갖는 인덱스를 반환한다.
# 가격이 최댓값인 데이터 정보
df.loc[df['가격'].idxmax()]

# 가격이 최댓값인 메뉴는?
df.loc[df['가격'].idxmax(), '메뉴']
'밀크티'
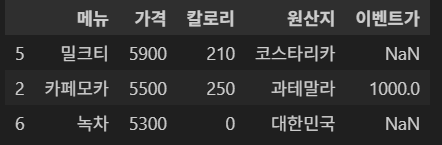
1-7. nlargest(), nsmallest()
nlargest()는 특정 컬럼에서 가장 큰 값 n개를 반환한다.
결과는 내림차순으로 정렬된다.
# 가격 중 큰 값 3개를 출력
df.nlargest(3, '가격')
nsmallest()는 가장 작은 값 n개를 반환한다.
결과는 오름차순으로 정렬된다.
df.nsmallest(4, '가격')

1-8. apply()
예를 들어 칼로리 100을 기준으로 먹어도 될지 결정하고자 할 때 100 미만이면 먹어도 되므로 Yes, 아니면 No를 출력하자.
def cal(x):
if x >= 100:
return "NO"
else:
return "YES"
df['먹어도 되나요'] = df['칼로리'].apply(cal)
df.head()

1-9. melt()
melt()는 데이터프레임을 재구조화하는 데 사용한다. (넓은 형태 -> 긴 형태)
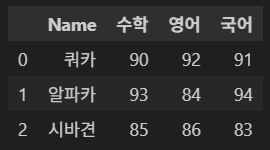
데이터를 생성한다.
import pandas as pd
df = pd.DataFrame({'Name': ['쿼카', '알파카', '시바견'],
'수학': [90, 93, 85],
'영어': [92, 84, 86],
'국어': [91, 94, 83]})
df
'넓은 형태'란 각 행이 한 사람의 모든 정보를 담고 있고 열은 다양한 변수(과목)를 나타낸다.
'긴 형태'란 각 행이 단 하나의 관측값만 갖고 다양한 변수들이 행으로 길게 나열되는 형태이다.
id_vars(필수) : 데이터를 재구조화할 때 유지하고 싶은 열들을 지정한다.
value_vars(선택) : 재구조화할 열들을 지정한다. 지정하지 않으면 id_vars를 제외한 모든 열이 사용된다.
pd.melt(df, id_vars=['Name'])

pd.melt(df, id_vars=['Name'], value_vars=['수학', '영어'])

'빅데이터 분석기사' 카테고리의 다른 글
| [빅분기 실기] 판다스 (pandas) 시계열 데이터 (datetime, Timedelta) (0) | 2024.11.10 |
|---|---|
| [빅분기 실기] 판다스 (pandas) 그룹핑 (0) | 2024.11.09 |
| [빅분기 실기] 판다스 (pandas) 값 변경. 문자열 (0) | 2024.11.09 |
| [빅분기 실기] 판다스 (pandas) 필터링, 결측치 처리 (0) | 2024.11.09 |
| [빅분기 실기] 판다스 (pandas) 데이터 추가, 변경. 정렬 (0) | 2024.11.09 |



