1. 문제 정의
미국의 인구조사 데이터 (1994)를 바탕으로 만들어진 데이터이다.
데이터에서 각 사람의 소득을 예측한다.
나이, 결혼 여부, 직종 등의 컬럼이 있다.
2. 라이브러리 및 데이터 불러오기
import pandas as pd
train = pd.read_csv('train.csv')
test = pd.read_csv('test.csv')
train

test
3. 탐색적 데이터 분석 (EDA)
데이터 크기, 자료형, 기초 통계 등 데이터가 어떻게 구성되었는지 파악하고 결측치, 이상치 등을 발견한다.
3-1. 데이터 샘플
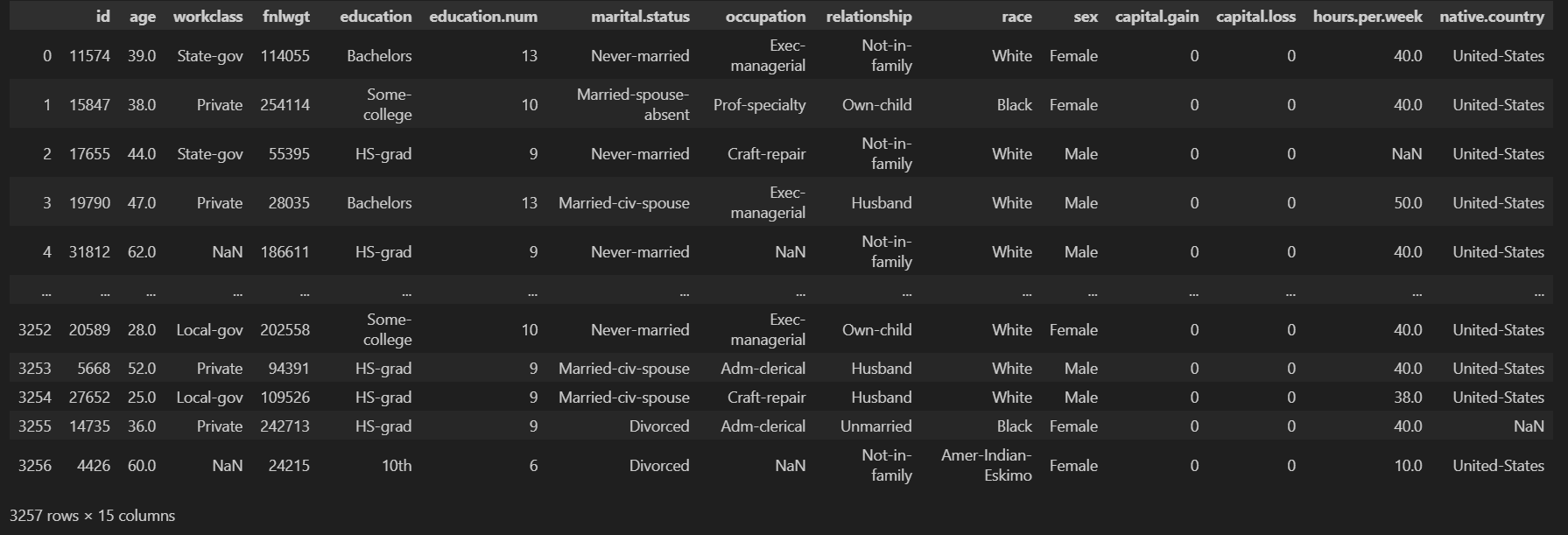
데이터를 확인하면 id, age, workclass,... , income 컬럼과 데이터를 확인할 수 있다.
수치형 (Numerical) 변수와 범주형 (categorical) 변수가 함께 있다.
income 컬럼이 target (label) 컬럼이다.
일반적으로 train 데이터에 target이 함께 있다면 가장 오른쪽 컬럼에 주로 있다.
3-2. 데이터 크기 shape
train.shape, test.shape

3-3. 자료형 info()
train.info()
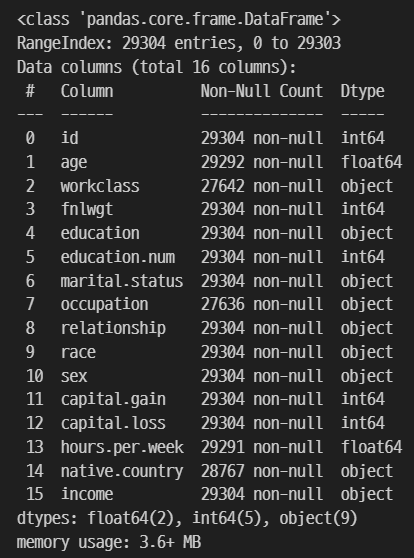
train 데이터 타입에는 float형 2개, int형 5개, object형 9개가 존재한다.
머신러닝의 입력 데이터로 활용하기 위해서 object형은 반드시 수치형 (float, int) 데이터로 변경해야 한다.
3-4. 기초 통계 describe() 수치형
train 데이터와 test 데이터의 수치형 컬럼 기초 통계 값을 확인할 수 있다.
train.describe()
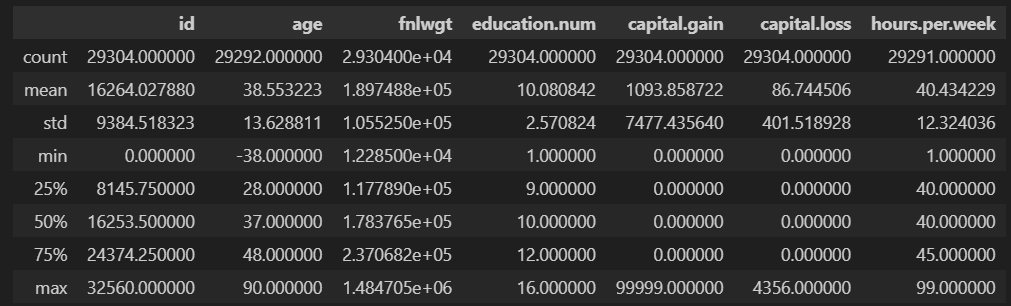
train 데이터의 'age' 컬럼을 보면 평균이 38세, 최솟값이 -38, 최댓값이 90인 것을 확인할 수 있다.
test.describe()
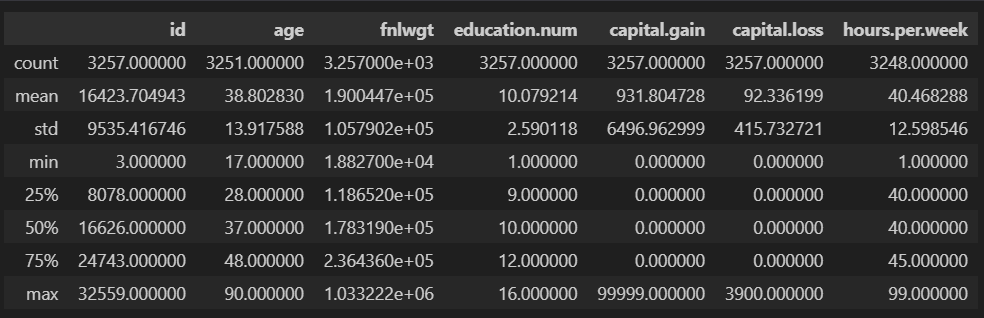
test 데이터의 'age' 컬럼의 최솟값은 17이다.
나이는 마이너스 값이 존재하지 않는다.
따라서 train에는 마이너스가 있고 test에는 마이너스가 없으므로 이상치로 의심할 수 있다.
3-5. 기초 통계 describe(include = 'object') 범주형
train.describe(include = 'O')

test.describe(include = 'O')

native.country 컬럼을 보면 카테고리 종류 (unique)가 train은 41개 test는 37개로 차이가 있다.
test에서 최빈값은 United-States이고 빈도 수는 2930이다.
3-6. 결측치
train.isnull().sum()
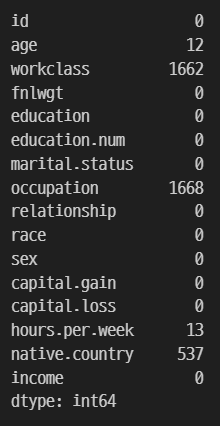
test.isnull().sum()
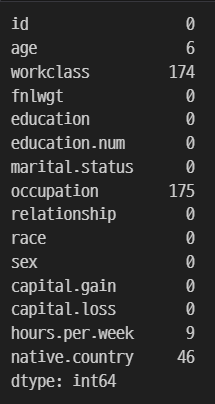
train, test 데이터 모두 age, workclass, occupation, hours.per.week, native.country 5개 컬럼에서 결측치를 확인할 수 있다.
3-7. target별 빈도수
value_counts()를 활용해 target(카테고리) 별 개수를 확인한다.
train['income'].value_counts()
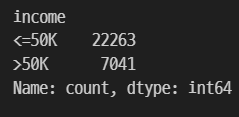
$50000 이하가 22263개, $50000 초과가 7041개 있다.
target에서 확인하고자 하는 것은 첫 번째 이진 분류인지, 두 번째 불균형 데이터인지다.
불균형 정도는 대략 7:3이다.
4. 데이터 전처리
4-1. 결측치 처리
1. 결측치 삭제
dropna()를 통해 결측치가 있는 행(레코드)을 제거할 수 있다.
print('처리전:', train.shape)
df = train.dropna()
print('처리후:', df.shape)
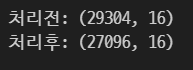
dropna()는 전체 데이터를 대상으로 결측치가 하나라도 있는 행은 모두 삭제한다.
특정 컬럼 데이터에서 결측이 있는 '행'을 제거하고 싶다면 dropna(subset = ['컬럼명'])을 사용한다.
df = train.dropna(subset=['native.country', 'workclass'])
df.isnull().sum()
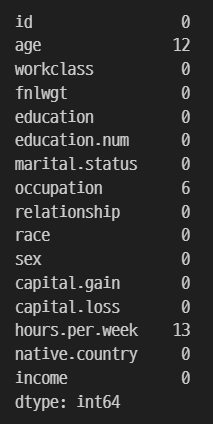
결측치가 있는 컬럼 전체를 삭제할 수도 있다.
dropna()에서 축을 axis = 1로 설정한다.
이 방법은 1개의 결측치가 있는 컬럼도 삭제한다.
print('처리전:', train.shape)
df = train.dropna(axis = 1)
print('처리후:', df.shape)
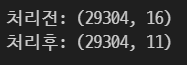
특정 컬럼만 삭제하는 방법은 drop을 사용한다.
print('처리전:', train.shape)
df = train.drop(['native.country', 'workclass'], axis = 1)
print('처리후:', df.shape)
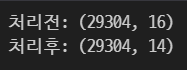
2. 결측치 채우기 (범주형)
범주형 데이터에서 결측치를 채울 때 주로 최빈값으로 대체한다.
특정 컬럼에서 mode()[0]을 통해 최빈값을 찾고, fillna()로 값을 채울 수 있다.
train['workclass'] = train['workclass'].fillna(train['workclass'].mode()[0])
train['native.country'] = train['native.country'].fillna(train['native.country'].mode()[0])
train.isnull().sum()
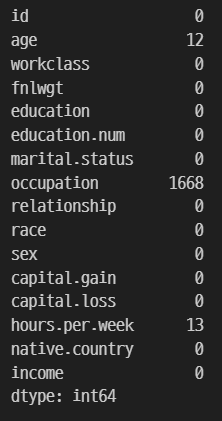
결측치를 새로운 카테고리로 분류할 수 있다.
임의의 표시로 결측 데이터를 'X'로 채울 수 있다.
X는 의미가 있는 것은 아니고 결측을 나타내는 유니크한 값으로 채웠다.
train['occupation'] = train['occupation'].fillna('X')
train.isnull().sum()
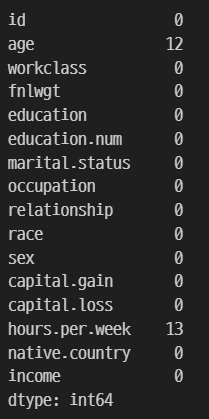
test 데이터에도 train 데이터와 동일하게 전처리를 실행한다.
test['workclass'] = test['workclass'].fillna(test['workclass'].mode()[0])
test['native.country'] = test['native.country'].fillna(test['native.country'].mode()[0])
test['occupation'] = test['occupation'].fillna('X')
test.isnull().sum()
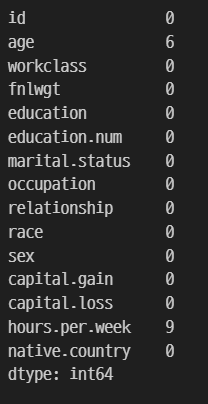
3. 결측치 채우기 (수치형)
'age'의 결측치는 평균값으로 'hours.per.week'의 결측치는 중앙값으로 채운다.
train['age'] = train['age'].fillna(int(train['age'].mean()))
test['age'] = test['age'].fillna(int(test['age'].mean()))
train['hours.per.week'] = train['hours.per.week'].fillna(train['hours.per.week'].median())
test['hours.per.week'] = test['hours.per.week'].fillna(test['hours.per.week'].median())
train.isnull().sum()
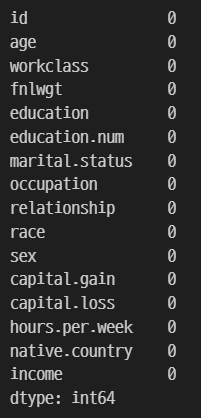
4-2. 이상치 처리
이상치(Outliers)는 일반적인 데이터 패턴에서 벗어난 값이다.
train 데이터에서 'age' 컬럼에 음수가 있었는데 이를 이상치로 판단하고 제거할 것이다.
print(train.shape)
train = train[train['age'] > 0]
print(train.shape)
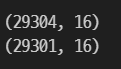
4-3. 인코딩
인코딩(Encoding)은 데이터를 컴퓨터가 이해하고 처리할 수 있는 형식으로 변환하는 과정이다.
범주형 (텍스트) 데이터를 숫자로 변환하는 과정인데, 머신러닝 모델에 입력 데이터로 사용하기 위한 필수 과정이다.
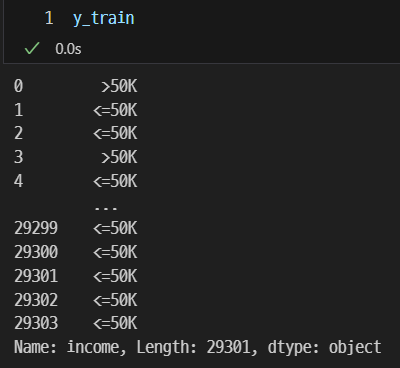
target은 범주형 데이터이고 인코딩을 진행하기 앞서 원-핫 인코딩 되는 것을 방지하기 위해 y_train 변수에 담아둔다.
pop()은 income 컬럼을 y_train에 대입하고, train의 income 컬럼을 삭제한다.
y_train = train.pop('income')
1. 원-핫 인코딩
pd.get_dummies(train)을 train 데이터 전체에 넣어주면 인코딩이 필요한 컬럼만 자동으로 인코딩이 진행된 후 결괏값을 반환한다.
pd.get_dummies()를 활용해 train과 test 원-핫 인코딩을 진행하고 전과 후의 컬럼 수를 확인한다.
train_oh = pd.get_dummies(train)
test_oh = pd.get_dummies(test)
print(train.shape, train_oh.shape)
print(test.shape, test_oh.shape)
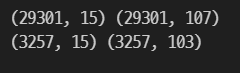
원-핫 인코딩 시 train과 test의 컬럼 수가 일치하지 않는다.
컬럼이 다르면 머신러닝 입력 데이터로 사용할 수 없다.
따라서 데이터를 합쳐 인코딩을 해야 한다.
concat()을 활용해 데이터를 위아래로 합친다.
get_dummies()로 합친 데이터를 원-핫 인코딩한다.
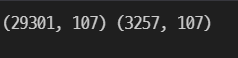
iloc을 활용해 데이터를 분할한다. (0 ~ len(train)-1 은 train_oh, len(train) ~ 나머지는 test_oh)
선택된 데이터를 새로운 변수에 옮겨 담을 때는 copy()를 붙여준다. (SettingWithCopyWarning 오류 방지)
data = pd.concat([train, test])
data_oh = pd.get_dummies(data)
train_oh = data_oh.iloc[:len(train)].copy()
test_oh = data_oh.iloc[len(train):].copy()
print(train_oh.shape, test_oh.shape)
2. 레이블 인코딩
레이블 인코딩할 object 자료형 컬럼명을 리스트 형태로 만든다.
cols = train.columns[train.dtypes == object]
cols

레이블 인코딩은 사이킷런(scikit-learn)에서 지원한다.
사이킷런은 머신러닝과 데이터 분석을 위한 파이썬 라이브러리다.
사이킷런에서 제공하는 LabelEncoder를 활용한다.
여러 컬럼에 레이블 인코딩을 적용하려면 각 컬럼에 대해 레이블 인코딩을 개별적으로 적용한다.
from sklearn.preprocessing import LabelEncoder
for col in cols:
le = LabelEncoder()
train.loc[:, col] = le.fit_transform(train.loc[:, col])
test.loc[:, col] = le.fit_transform(test.loc[:, col])
train.head()

4-4 스케일링
스케일링은 수치형 데이터의 범위를 조정하는 작업이다.
스케일링을 적용할 수치형 컬럼명을 리스트로 만든다.
cols = train.columns[train.dtypes != object][1:]
cols

1. 민맥스 스케일링 (Min-Max Scaling)
민맥스 스케일링은 데이터를 0과 1 사이로 변환한다.
금액이 1000원부터 100000원까지 있다면 1000이 0이 되고 100000이 1이 된다.
from sklearn.preprocessing import MinMaxScaler
train_copy, test_copy = train.copy(), test.copy()
scaler = MinMaxScaler()
display(train_copy[cols].head())
train_copy[cols] = scaler.fit_transform(train_copy[cols])
test_copy[cols] = scaler.transform(test_copy[cols])
display(train_copy[cols].head())
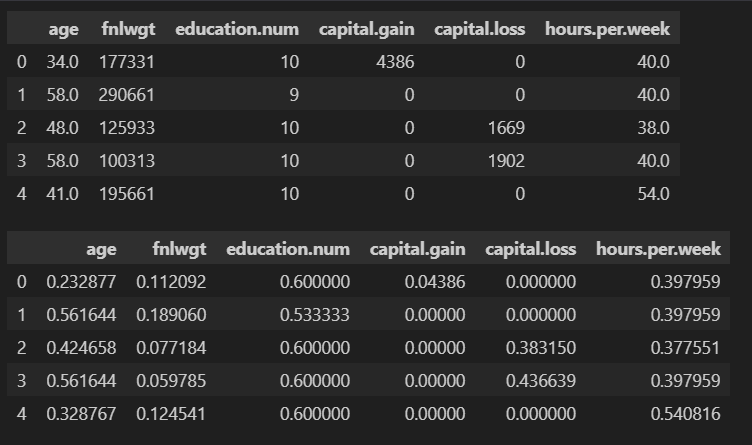
※ display를 활용해서 스케일링 전과 후의 결과를 표 형태로 출력했다.
2. 스탠더드 스케일링 (Standard Scaling)
스탠더드 스케일링은 데이터를 평균이 0, 표준편차가 1인 분포로 변환한다.
from sklearn.preprocessing import StandardScaler
train_copy, test_copy = train.copy(), test.copy()
scaler = StandardScaler()
display(train_copy[cols].head())
train_copy[cols] = scaler.fit_transform(train_copy[cols])
test_copy[cols] = scaler.transform(test_copy[cols])
display(train_copy[cols].head())
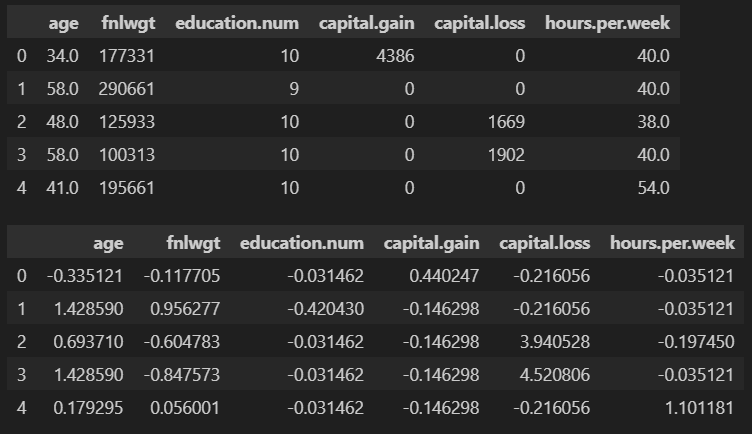
3. 로버스트 스케일링 (Robust Scaling)
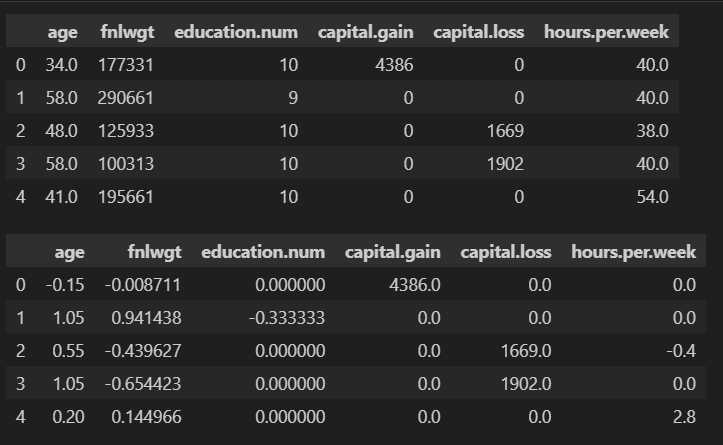
로버스트 스케일링은 각 값의 중앙값을 빼고 1 사분위수(Q1)와 3 사분위수(Q3)의 차이(IQR)로 나누는 방법이다.
다른 스케일링에 비해 이상치의 영향을 덜 받는 특징이 있다.
capital.gain은 대부분 0에 가깝다.
capitial.gain의 Q1과 Q3가 0에 가깝다면 컬럼의 대부분의 값들이 변하지 않을 수 있다.
이번 스케일링은 복사본이 아닌 원 데이터에 적용했다.
from sklearn.preprocessing import RobustScaler
train_copy, test_copy = train.copy(), test.copy()
scaler = RobustScaler()
display(train_copy[cols].head())
train_copy[cols] = scaler.fit_transform(train_copy[cols])
test_copy[cols] = scaler.transform(test_copy[cols])
display(train_copy[cols].head())
train = train_copy.copy()
test = test_copy.copy()
5. 검증 데이터 나누기
검증 데이터를 나누는 이유는 학습된 모델의 성능을 평가하고 개선하기 위함이다.
검증 데이터를 활용해 모델의 성능을 평가하고 데이터 전처리 단계 또는 하이퍼파라미터 튜닝을 통해 개선할 수 있다.
사이킷런에서 제공하는 train_test_split()을 활용해 데이터를 분리한다.
from sklearn.model_selection import train_test_split
X_train, X_val, y_train, y_val = train_test_split(train, y_train, test_size = 0.2, random_state = 0)
X_train.shape, X_val.shape, y_train.shape, y_val.shape

6. 머신러닝 학습 및 평가
머신러닝 모델 중 의사결정 나무 모델은 학습을 통해 트리 구조를 만든다.
의사결정 나무는 어떤 과정을 통해 결과가 도출되었는지 설명하기 쉽다.
하지만 과적합되기 쉬워 성능에 한계가 있다.
이를 보완하기 위해 여러 개의 모델을 학습시켜 사용한다.
이를 앙상블이라고 한다. 앙상블의 기법에는 두 가지가 있는데 배깅(bagging), 부스팅 (boosting)이다.
대표 모델로 배깅은 랜덤포레스트(Random Forest), 부스팅에는 라이트지비엠 (LightGBM)이 있다.
6-1. 랜덤포레스트 (Random Forest)
랜덤포레스트는 여러 개의 의사결정 나무를 기반으로 한 앙상블 학습 알고리즘이다.
from sklearn.ensemble import RandomForestClassifier
rf = RandomForestClassifier(random_state = 0)
rf.fit(X_train, y_train)
pred = rf.predict_proba(X_val)
print(rf.classes_)
pred[:10]
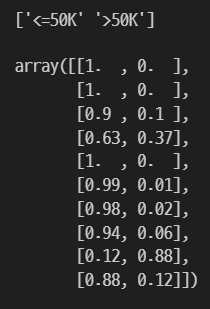
컬럼은 '<=50K', '>50K'이고 10개의 각각의 확률을 나타내 보았다.
6-2. 평가지표
1. ROC_AUC
ROC_AUC 점수를 평가할 때는 확률값이 필요하다.
머신러닝에서는 예측할 때 확률값을 예측할 수 있는 predict_proba()를 사용했다.
from sklearn.metrics import roc_auc_score
roc_auc = roc_auc_score(y_val, pred[:,1])
print('roc_auc: ', roc_auc)

2. Accuracy (정확도)
정확도를 평가할 때는 predict()를 활용한다.
predict()는 예측된 각 클래스(레이블)를 반환한다.
pred = rf.predict(X_val)
pred[:10]

정확도의 결과 점수를 확인한다.
from sklearn.metrics import accuracy_score
accuracy = accuracy_score(y_val, pred)
print('accuracy: ', accuracy)
3. F1 스코어
F1 스코어는 정밀도(Precision)와 재현율(Recall)의 조화 평균으로 계산되는 평가지표이며 높을수록 좋다.
F1 스코어는 양성 클래스를 1로 가정하는데, target이 문자로 구성되어 있으면 어떤 값이 양성 클래스인지 pos_label를 사용해 지정해야 한다.
from sklearn.metrics import f1_score
f1 = f1_score(y_val, pred, pos_label = '>50K')
print('f1_score: ', f1)

6-3 라이트지비엠 (LightGBM)
라이트지비엠은 Gradient Boosting 기반의 앙상블 학습 알고리즘이고, 머신러닝 모델 중 정형 데이터를 다룰 때 매우 인기 있는 모델이다.
cols = X_train.columns[X_train.dtypes == 'O']
for col in cols:
X_train[col] = X_train[col].astype('int64')
X_val[col] = X_val[col].astype('int64')
import lightgbm as lgb
lgbmc = lgb.LGBMClassifier(random_state = 0, verbose = -1)
lgbmc.fit(X_train, y_train)
pred = lgbmc.predict_proba(X_val)
roc_auc = roc_auc_score(y_val, pred[:, 1])
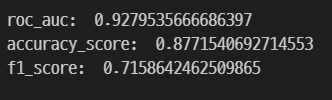
print('roc_auc: ', roc_auc)
pred = lgbmc.predict(X_val)
accuracy = accuracy_score(y_val, pred)
print('accuracy_score: ', accuracy)
f1 = f1_score(y_val, pred, pos_label = '>50K')
print('f1_score: ', f1)
7. 예측 및 결과 파일 생성
학습된 라이트지비엠 모델을 활용해 test 데이터를 넣고 predict_proba를 실행하면 예측 확률값을 반환받는다.
cols = test.columns[test.dtypes == 'O']
test[cols] = test[cols].astype('int64')
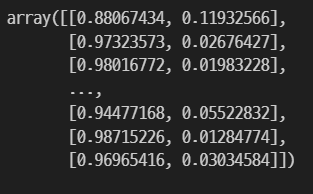
pred = lgbmc.predict_proba(test)
pred
예측값을 데이터프레임으로 변경하고 컬럼명을 'pred'로 한다.
저장할 때는 반드시 index=False 파라미터를 적용한다.
submit = pd.DataFrame({'pred': pred[:, 1]})
submit.to_csv('result.csv', index=False)
'빅데이터 분석기사' 카테고리의 다른 글
| [빅분기 실기] 판다스 (Pandas) 데이터 프레임 합치기 (0) | 2024.11.16 |
|---|---|
| [빅분기 실기] 판다스 (pandas) 시계열 데이터 (datetime, Timedelta) (0) | 2024.11.10 |
| [빅분기 실기] 판다스 (pandas) 그룹핑 (0) | 2024.11.09 |
| [빅분기 실기] 판다스 (pandas) 내장 함수 (0) | 2024.11.09 |
| [빅분기 실기] 판다스 (pandas) 값 변경. 문자열 (0) | 2024.11.09 |



