1. 데이터프레임과 시리즈
판다스의 데이터는 시리즈 (Series)와 데이터프레임(DataFrame)으로 구성되어 있다.
시리즈는 1차원 형대고, 데이터프레임은 행(rows)과 열(columns)이 있는 2차원 (표) 형태다.
1-1. 행과 열
행은 각 데이터/레코드이고 열은 컬럼 전체다. 즉 행은 가로이고 열은 세로이다.
판다스에서 축(axis)을 숫자로 나타낼 때 행은 0, 열은 1로 표시하므로 숫자 순서대로 "행(0)렬(1)"로 기억한다.
1-2. 판다스의 별칭
import pandas as pd
1-3. 시리즈
시리즈는 pd.Series(데이터)로 만들 수 있다. 데이터는 리스트를 활용해 만들 수 있다.
출력을 하면 인덱스와 값이 출력되고 자료형은 'object'다.
판다스에서 object형은 주로 문자열 데이터를 나타내는 데 사용된다.
menu = pd.Series(['비빔밥', '김치찌개', '된장찌개'])
menu
0 비빔밥
1 김치찌개
2 된장찌개
dtype: object
숫자를 리스트 형태로 만들고 pd.Series()로 감싸게 되면 시리즈로 변경된다. 시리즈 값의 자료형 (타입)은 int다.
판다스는 리스트에 포함된 데이터 타입을 기반으로 시리즈의 데이터 타입을 자동으로 결정한다.
price = pd.Series([10000, 9000, 8000])
price
0 10000
1 9000
2 8000
dtype: int64
1-4. 데이터프레임 (DataFrame)
데이터프레임은 pd.DataFrame({"컬럼명": 데이터})로 만든다.
앞서 만든 2개의 시리즈를 합쳐 데이터프레임으로 만든다.
pd.DataFrame({
"메뉴": menu,
"가격": price
})

데이터프레임을 만들 때 시리즈를 거치지 않고 바로 만들 수 있다.
일반적으로 데이터프레임을 담는 변수명은 DataFrame의 약자인 df를 주로 사용한다.
df = pd.DataFrame({
"메뉴": ['비빔밥', '김치찌개','된장찌개'],
'가격': [10000, 9000, 8000],
'원산지': ['국내산','국내산','국내산']
})
df
1-5. 컬럼 선택
df['컬럼명']으로 특정 컬럼만 선택해 표시할 수 있다.
df['메뉴']
0 비빔밥
1 김치찌개
2 된장찌개
Name: 메뉴, dtype: object
df.컬럼명과 같이 "."을 사용하는 방법도 있지만 컬럼명에 공백이 있으면 에러가 발생한다.
1-6. 데이터프레임과 시리즈 자료형
1개의 컬럼을 데이터프레임으로 만드는 방법은 대괄호로 한 번 더 묶어준다.
df[['메뉴']]
복수의 컬럼을 선택할 때는 대괄호 2개를 사용한다.
df[['메뉴', '가격']]
컬럼을 복수로 선택할 때는 주로 리스트를 활용한다.
cols = ['메뉴', '가격']
df[cols]
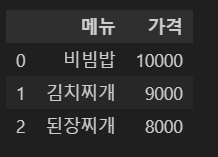
따라서 df는 데이터프레임, df['컬럼명']은 시리즈, df[['컬럼명']]은 데이터프레임이다.
print("df :", type(df))
print("df['가격'] : ", type(df['가격']))
print("df[['가격']] : ", type(df[['가격']]))
df : <class 'pandas.core.frame.DataFrame'>
df['가격'] : <class 'pandas.core.series.Series'>
df[['가격']] : <class 'pandas.core.frame.DataFrame'>
2. 데이터 저장 및 불러오기
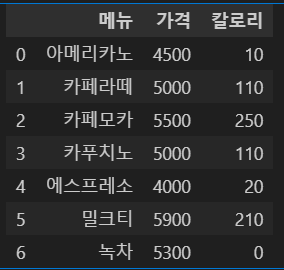
카페 메뉴판 데이터를 만들기 위해 메뉴, 가격, 칼로리가 있는 데이터 프레임을 만들고 각 데이터 값을 입력한다.
import pandas as pd
df = pd.DataFrame({
"메뉴" : ['아메리카노', '카페라떼', '카페모카', '카푸치노', '에스프레소', '밀크티', '녹차'],
"가격" : [4500, 5000, 5500, 5000, 4000, 5900, 5300],
"칼로리" : [10, 110, 250, 110, 20, 210, 0],
})
df
2-1. csv로 저장
데이터프레임을 저장할 때는 df.to_csv('파일명')으로 저장한다.
df.to_csv('temp.csv')
2-2. csv 불러오기
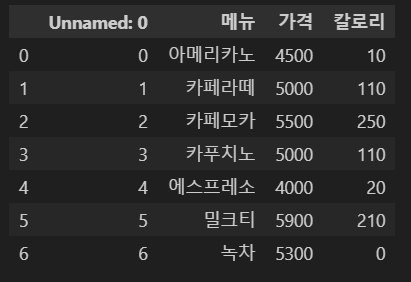
pd.read_csv('파일명')으로 csv 데이터를 불러올 수 있다.
출력된 결과를 보면 알 수 없는 "Unnamed: 0" 컬럼이 보인다.
데이터를 저장할 때 기본 설정으로 기존 인덱스가 값으로 함께 저장된 것이다.
따라서 가장 왼쪽에 있는 인덱스는 pd.read_csv()로 데이터를 불러올 때 새로 생성된 인덱스이다.
temp_df = pd.read_csv('temp.csv')
temp_df
2-3. csv 저장 옵션
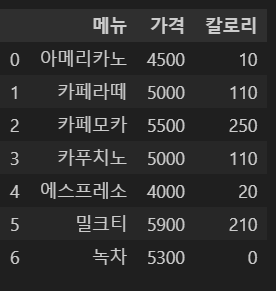
인덱스를 제외하고 저장하기 위해 index=False로 설정한다.
df.to_csv('cafe.csv', index=False)
df = pd.read_csv('cafe.csv')
df
※ 데이터 불러오기 옵션
1. index_col
인덱스를 사용할 컬럼명 또는 열의 번호를 지정한다.
pd.read_csv('cafe.csv', index_col = '메뉴')
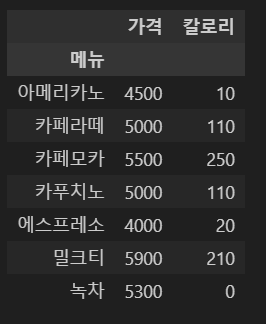
2. usecols
불러올 컬럼명 또는 열의 번호를 지정한다.
pd.read_csv('cafe.csv', usecols = ['메뉴', '칼로리'])
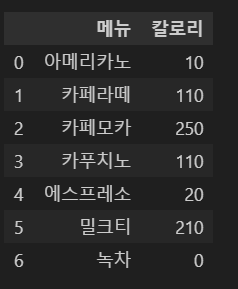
3. parse_dates
문자열로 된 컬럼을 날짜 datetime으로 변경할 수 있다. 이를 파싱(parsing)이라고 한다.
pd.read_csv('data.csv', parse_dates = ['컬럼명'])
4. encoding
일반적으로 판다스는 'UTF-8'을 기본 인코딩 방식으로 사용한다.
만약 한국어가 포함된 텍스트 파일이 UTF-8이 아닐 경우 글자가 깨지는 현상을 볼 수 있다.
이를 방지하기 위해 'cp949' 또는 'euc-kr'로 설정한다.
pd.read_csv('data.csv', encoding='cp949')
pd.read_csv('data.csv', encoding='euc-kr')
'빅데이터 분석기사' 카테고리의 다른 글
| [빅분기 실기] 판다스 (pandas) 값 변경. 문자열 (0) | 2024.11.09 |
|---|---|
| [빅분기 실기] 판다스 (pandas) 필터링, 결측치 처리 (0) | 2024.11.09 |
| [빅분기 실기] 판다스 (pandas) 데이터 추가, 변경. 정렬 (0) | 2024.11.09 |
| [빅분기] 판다스 (pandas) 인덱싱. 슬라이싱 (loc, iloc) (0) | 2024.11.06 |
| [빅분기] 판다스 (pandas) - 탐색적 데이터 분석 (EDA). 자료형 변환. 컬럼 추가. 데이터 삭제 (0) | 2024.11.02 |



