1. 탐색적 데이터 분석 (Exploratory Data Analysis, EDA)
데이터를 탐색하고 이해하기 위해 수행한다.
일반적으로 데이터는 한눈에 관찰할 수 없다. 눈으로 식별할 수 있는 크기라도 시간이 많이 소요된다.
따라서 탐색적 데이터 분석 과정을 통해 데이터를 다양한 각도에서 관찰하고 이해해야 한다.
1-1. 데이터 프레임 샘플 확인
head(N)은 데이터프레임의 상위 N개의 행을 반환한다.
N은 자연수이고 기본값은 5이다.
import pandas as pd
df = pd.read_csv('cafe.csv') # cafa.csv 만드는 방법 참고 https://kdh9797-devwiki.tistory.com/77
df.head()

df.head(2)
tail은 데이터프레임의 하위 N개의 행을 반환한다.
N은 자연수이고 기본값은 5이다.
df.tail()
df.tail(3)
sample(N)은 데이터프레임에서 임의로 샘플링해 N개의 행을 반환한다.
N은 자연수이고 기본값은 1이다.
실행할 때마다 다른 결과를 보여준다.
df.sample()
df.sample(3)
1-2. 데이터프레임 크기
전체 데이터의 크기를 확인할 때는 df.shape을 활용한다.
>> df.shape
(7, 3)
※ shape은 데이터프레임의 속성이어서 괄호가 없고, head(), tail()은 함수 (메서드) 형태라서 괄호가 있다.
1-3. 컬럼별 자료형
데이터프레임 안 컬럼의 자료형은 info()를 통해 확인한다.
Dtype에서 문자는 object, 숫자는 int로 표시된다.
df.info()
1-4. 상관관계
상관관계는 corr()를 통해 확인한다.
df.corr(numeric_only = True)
가격과 칼로리는 0.7의 양의 상관관계를 확인할 수 있다.
1-5. 범주형 데이터 탐색
자동차의 종류와 크기를 나타낸 중복 값이 있는 데이터다.
df_car = pd.DataFrame({
"car" : ['Sedan', 'SUV', 'Sedan', 'SUV', 'SUV', 'SUV', 'Sedan', 'Sedan', 'Sedan', 'Sedan', 'Sedan'],
"size" : ['S', 'M', 'S', 'S', 'M', 'M', 'L', 'S', 'S', 'M', 'S']
})
df_car.head()

1-6. 고유한 값
데이터프레임에서 컬럼별로 고유한 값의 개수를 찾을 때 nunique()를 사용한다.
df_car.nunique()
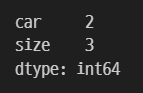
car 종류는 2개, size 종류는 3개가 있다는 것을 알 수 있다.
하지만 nunique()는 종류의 수는 파악할 수 있지만 어떤 데이터인지 알 수 없다.
구체적인 항목을 파악하기 위해 unique()를 사용한다.
df_car['car'].unique()
df_car['size'].unique()


value_counts()는 항목별로 개수를 출력해 데이터를 탐색하는 데 사용된다.
print(df_car['car'].value_counts())
print(df_car['size'].value_counts())
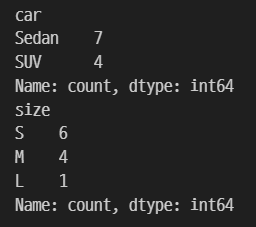
1-7 기술통계
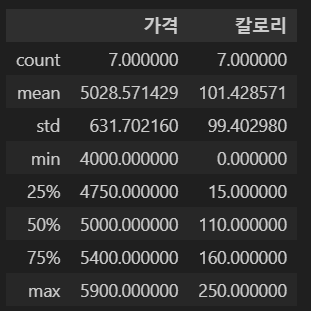
데이터의 기술통계량은 describe()를 통해 확인할 수 있다.
describe()는 기본적으로 수치형 데이터 (int, float 등)만 적용해 결과를 확인할 수 있다.
| count | 값이 있는 데이터 수 |
| mean | 평균 |
| std | 표준편차 |
| min | 최솟값 |
| 00% | 백분위수에서 % |
| max | 최댓값 |
df.describe()
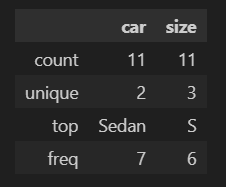
데이터 타입이 object인 기술통계를 확인할 때는 include 파라미터를 사용한다.
"O" 또는 "object"를 입력한다.
| count | 값이 있는 데이터 수 |
| unique | 고유한 데이터 수 (종류) |
| top | 가장 많이 나오는 값 (최빈값) |
| freq | 가장 많이 나오는 값의 빈도 수 |
df_car.describe(include = "O")
2. 자료형 변환
문제 상황에 따라 문자를 숫자로 변환하거나 실수형을 정수형으로 변환할 때가 있다.
다음 데이터는 가격은 float형, 칼로리는 object형으로 만들어진 데이터이다.
import pandas as pd
df = pd.DataFrame({
"메뉴" : ['아메리카노', '카페라떼', '카페모카', '카푸치노', '에스프레소', '밀크티', '녹차'],
"가격" : [4500.0, 5000.0, 5500.0, 5000.0, 4000.0, 5900.0, 5300.0],
"칼로리" : ['10', '110', '250', '110', '20', '210', '0'],
})
df.info()
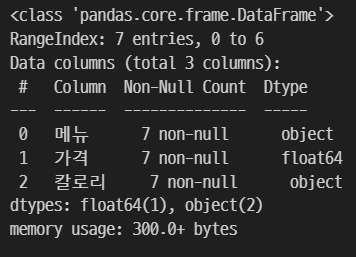
2-1. int로 변환
astype()을 사용하여 자료형을 변경한다.
df['가격'] = df['가격'].astype('int')
df.info()
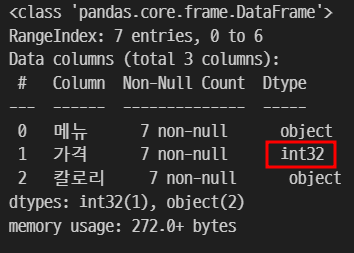
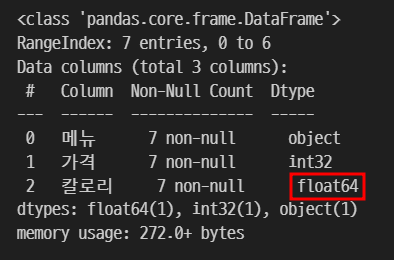
2-2. float로 변환
object 자료형인 칼로리 컬럼을 float로 변경한다.
이때 칼로리 컬림이 정수형으로 변경 가능한 데이터라면 문제가 없지만, 문자 데이터가 있다면 에러가 발생한다.
df['칼로리'] = df['칼로리'].astype('float')
df.info()
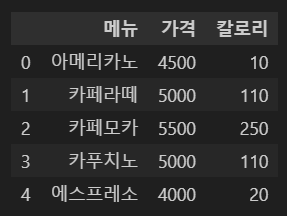
3. 컬럼 추가
현재 데이터프레임은 다음과 같다.
import pandas as pd
df = pd.read_csv('cafe.csv') # cafa.csv 만드는 방법 참고 https://kdh9797-devwiki.tistory.com/77
df.head()
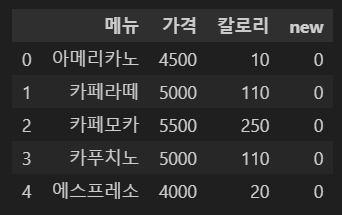
새로운 컬럼을 추가할 때는 df ['새 칼럼명']과 같이 작성한다. 그리고 임의의 값 0을 대입한다.
df['new'] = 0
df.head()
3-1. 기존 컬럼을 사용한 계산
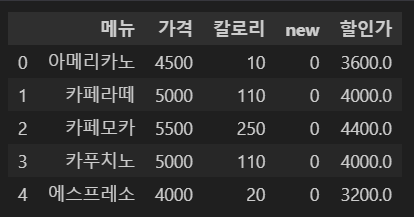
'할인가'라는 새로운 컬럼을 만들어 메뉴별 정상가에 20%를 할인한 금액을 새 컬럼에 대입한다.
df['할인가'] = df['가격'] * (1-0.2)
df.head()
4. 데이터 삭제
데이터를 삭제할 때는 행(row)을 삭제하는 것과 열(column)을 삭제하는 것이 있다.
이를 구분하기 위해 '축(axis)'이라는 개념을 사용한다.
축은 데이터의 방향으로 0은 행, 1은 열을 나타낸다.
특정 행을 삭제하고 싶으면 axis=0을 특정 열을 삭제하고 싶으면 axis=1을 사용한다.
drop() 함수를 사용하여 축을 선택하는지에 따라 행 또는 열을 삭제한다.
먼저 데이터를 불러온다.
df = pd.read_csv('cafe.csv')
df.head()
4-1. 행 삭제
df.drop("index 명", axis = 0)을 통해 삭제할 수 있다.
이때 특정 행을 삭제했지만 결괏값이 자동으로 저장되지는 않는다.
따라서 inplace 파라미터를 활용해 저장한다.
inplace의 기본값은 False고 drop 결괏값을 저장하지 않는다.
inplace를 True로 설정하면 drop 결괏값이 저장된다.
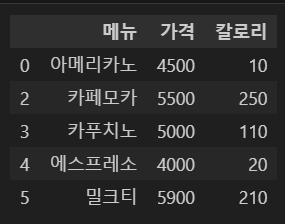
df.drop(1, axis=0, inplace=True)
df.head()
4-2. 컬럼(열) 삭제
df.drop("index 명", axis = 1)을 통해 삭제할 수 있다.
저장할 때 inplace 대신 대입 (=) 연산자를 통해 drop 결과를 저장할 수 있다.
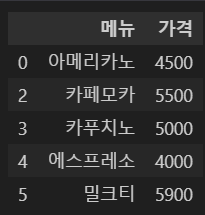
df = df.drop('칼로리', axis=1)
df.head()
4-3. 삭제 후 저장 방법
| 구분 | 예 | 반환 값 |
| inplace 사용 | dr.drop('가격', axis = 1, inplace = True) | 없음 |
| 대입 연산자 (=) 사용 | df = df.drop('가격', axis = 1) | 있음 |
대입 연산자와 inplace를 함께 사용하면 안 된다.
'빅데이터 분석기사' 카테고리의 다른 글
| [빅분기 실기] 판다스 (pandas) 값 변경. 문자열 (0) | 2024.11.09 |
|---|---|
| [빅분기 실기] 판다스 (pandas) 필터링, 결측치 처리 (0) | 2024.11.09 |
| [빅분기 실기] 판다스 (pandas) 데이터 추가, 변경. 정렬 (0) | 2024.11.09 |
| [빅분기] 판다스 (pandas) 인덱싱. 슬라이싱 (loc, iloc) (0) | 2024.11.06 |
| [빅분기 실기] 판다스 (Pandas) - 데이터 프레임과 시리즈. 데이터 저장 및 불러오기 (0) | 2024.11.02 |



