1. 데이터 추가 및 변경
1-1. 결측치(NaN) 대입
import pandas as pd
df = pd.read_csv('cafe.csv') # cafa.csv 만드는 방법 참고 https://kdh9797-devwiki.tistory.com/77
df.head()

'원산지'라는 새로운 컬럼을 만들고 데이터는 '값없음'을 의미하는 NaN (Not a Number)을 대입한다.
NaN (결측치) 이 있는 데이터를 만든다. NaN은 numpy 라이브러리를 통해 만들 수 있다.
※ 넘파이 (numpy)
파이썬 라이브러리로 빠르게 수치 연산하는 것이 특징이다.
연산량이 많은 딥러닝에서 주로 사용한다.
결측치가 있는 데이터셋을 만들기 위해 넘파이 라이브러리를 불러오고, 원산지 컬럼에 np.nan을 대입한다.
import numpy as np
df['원산지'] = np.nan
df
1-2. loc를 활용한 값 변경
특정 컬럼 범위의 값을 대체할 때 loc [인덱스명(범위), 컬럼명(범위)]가 활용된다.
df.loc[0, '원산지'] = '콜롬비아'
df.loc[2:3, '원산지'] = '과테말라'
df.head()
1-3. loc를 활용한 값 추가
loc의 대괄호 안에 새 인덱스명을 넣고 값을 대입한다.
인덱스명은 숫자가 아닌 문자도 가능하다.
리스트 형태로 데이터를 추가할 수 있다.
df.loc['시즌'] = ['크리스마스라떼', 6000, 300, '한국']
df.tail()
1-4. loc와 딕셔너리를 활용한 값 추가
리스트가 아닌 딕셔너리 형태로 새로운 데이터 행을 추가할 수 있다.
리스트의 경우 반드시 행의 컬럼 수와 리스트의 데이터 수가 일치해야 한다.
딕셔너리는 특정 컬림이 없다면 NaN으로 입력된다.
df.loc[7] = {'메뉴':'달콤커피', '가격':2000, '칼로리':20}
df.tail()
※ 새로운 csv 파일로 저장 (참고)
추후 작업을 위해 새로운 csv 파일로 저장한다.
df.drop('시즌', axis=0, inplace=True)
df.to_csv('cafe2.csv', index=False)
2. 정렬
2-1. 정렬 방법
sort_index()는 인덱스 기준, sort_values() 데이터 값 기준으로 정렬한다.
기본 설정은 오름차순이다. 내림차순 정렬은 ascending을 False로 대입한다.
| 정렬 | 파라미터 | 기본값 |
| 오름차순 | ascending = True | 기본값 (생략가능) |
| 내림차순 | ascending = False |
2-2. 인덱스 기준 정렬
인덱스를 내림차순으로 정렬해 보자.
df.sort_index(ascending=False)
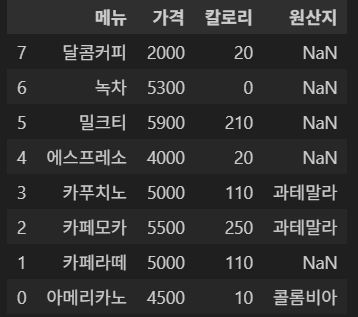
2-3. 데이터 값 기준 정렬
sort_values()를 사용할 때 반드시 들어가야 할 파라미터는 by='컬럼명'이다. ('by='는 생략 가능)
메뉴 컬럼을 기준으로 내림차순으로 정렬하자.
df.sort_values('메뉴', ascending=False)
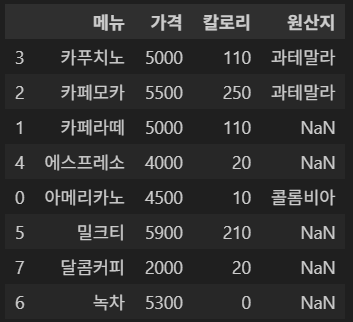
2-4. 2개 이상의 기준 정렬
정렬하고자 하는 컬럼이 2개 이상일 때, 컬럼마다 오름차순, 내림차순이 다를 수 있다.
이 때는 순서에 맞게 리스트 형태로 대입한다.
inplace를 활용해 변경 사항을 저장할 수 있다.
df.sort_values(['가격','메뉴'], ascending=[False, True], inplace=True)
df
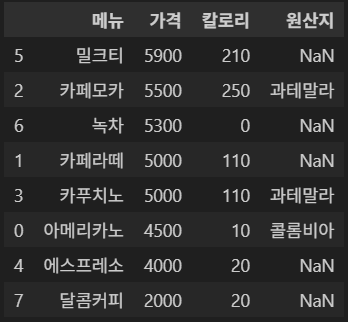
2-5. 인덱스 초기화
정렬이 변경된 상태에서 인덱스를 새로 만들고 싶을 때 reset_index()를 활용한다.
인덱스가 0부터 새롭게 만들어진다.
기존 인덱스는 새로운 컬럼에 저장된다.
df.reset_index()

기존 인덱스가 필요 없다면 drop=True로 설정한다.
df.reset_index(drop=True)
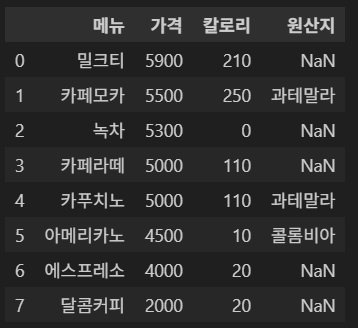
'빅데이터 분석기사' 카테고리의 다른 글
| [빅분기 실기] 판다스 (pandas) 값 변경. 문자열 (0) | 2024.11.09 |
|---|---|
| [빅분기 실기] 판다스 (pandas) 필터링, 결측치 처리 (0) | 2024.11.09 |
| [빅분기] 판다스 (pandas) 인덱싱. 슬라이싱 (loc, iloc) (0) | 2024.11.06 |
| [빅분기] 판다스 (pandas) - 탐색적 데이터 분석 (EDA). 자료형 변환. 컬럼 추가. 데이터 삭제 (0) | 2024.11.02 |
| [빅분기 실기] 판다스 (Pandas) - 데이터 프레임과 시리즈. 데이터 저장 및 불러오기 (0) | 2024.11.02 |



